匿名网络身份面临新挑战;大模型快速锁定真实用户,隐私保护需重新审视。


在数字时代,网络匿名曾被视为一种可靠的保护机制,让人们能够自由表达观点而不必担心个人信息泄露。然而,随着人工智能技术的迅猛发展,这种传统认知正面临严峻考验。研究显示,大型语言模型能够通过分析用户在论坛上的零散发言,显著提高识别匿名账户背后真实身份的可能性。这种能力不仅速度快,而且操作相对简便,使得在线隐私的界限变得模糊起来。
来自瑞士苏黎世联邦理工学院以及相关人工智能机构的学者们开展了一项深入探讨。他们在多个知名平台如HackerNews和Reddit上进行了系统测试。结果表明,通过收集匿名帖子的内容,大模型可以提取出与身份相关的各种特征,比如写作风格、兴趣偏好以及生活细节。这些特征随后被用于匹配公开可访问的资料,从而实现跨平台的身份关联。在特定条件下,这种方法的精确率能够达到较高水平,而传统人工或规则-based方式则难以企及类似效果。

这项研究的攻击流程分为几个关键步骤:首先从匿名文本中提炼出潜在的身份线索,其次利用语义搜索寻找可能的候选对象,然后通过逻辑推理筛选出最匹配的结果,最后进行置信度评估以提升可靠性。这种结构化的方法让整个过程变得高效且可扩展。相比之下,早期的去匿名化尝试往往依赖结构化数据,如观看记录或地理位置信息,而如今大模型直接处理自由文本,展现出更强的适应性。
隐私风险随之凸显。用户在网上随意分享的观点、喜好或日常琐事,都可能成为锁定身份的突破口。例如,讨论家乡特色、职业经历或特定兴趣时,无意中透露的细节会被AI捕捉并整合分析。这不仅可能导致个人信息暴露,还会带来人肉搜索、针对性广告或其他形式的干扰。研究者强调,长期以来人们依赖的“实际隐蔽性”——即认为去匿名化成本过高而难以大规模实施——已被颠覆。未来,随着模型能力的持续提升,这种威胁将进一步加剧。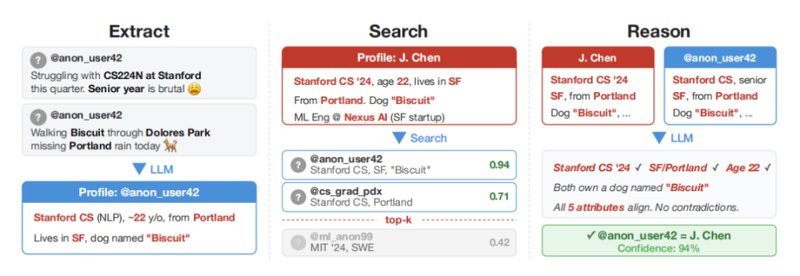
为了验证方法的有效性,研究团队构建了多个数据集。其中一个结合了HackerNews的帖子与LinkedIn的公开资料,通过跨平台引用建立关联;另一个聚焦Reddit电影讨论社区,观察用户分享内容数量对识别难度的影响;还有一个则将单一用户的帖子按时间拆分,模拟不同匿名身份的匹配场景。这些实验全面展示了技术的潜力,同时也提醒平台和用户需重视数据保护策略。
在采访中,一位研究参与者指出,这种能力代表了从结构化数据向非结构化文本的重大转变。过去的方法需要明确链接,而现在AI像人类侦探一样逐步推理,浏览网络内容并缩小范围。这种类人智能的介入,让去匿名化从高门槛任务转为相对可及的操作。面对这一现实,网络参与者应更谨慎地管理在线足迹,避免无谓透露可链接个人信息。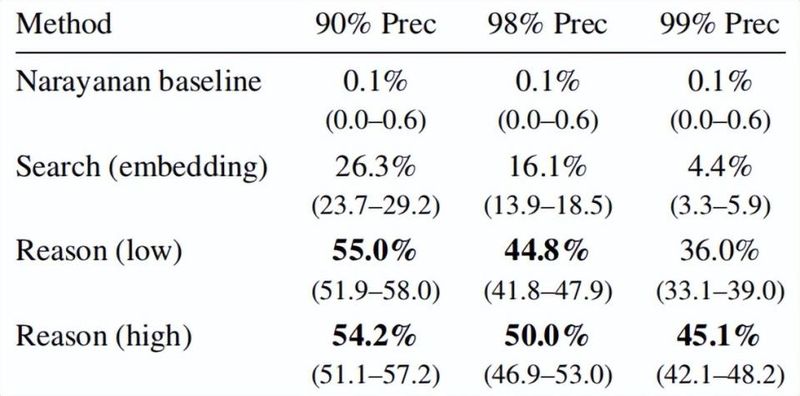
总体而言,这项进展引发了对在线匿名机制的深刻反思。匿名本意是为促进开放讨论提供空间,但技术变革要求我们重新评估隐私边界。用户、教育者和平台方都需要共同努力,探索更有效的防护手段,如增强匿名工具或限制数据聚合,以维护数字空间的信任与安全。唯有如此,才能在技术创新与个人权益之间找到平衡点。


